Hard pass Kubernetes, Hello Nomad!

Lob offers Direct Mail designed for developers
It can be argued that embracing two of our core values at Lob—Move Fast & Take Action and Be Bold—has made us a major player in the direct mail automation space. But a possible downside of adopting such audacity is that it could lead to heterogeneous technology and processes (or in other words, a hot mess).
To avoid such a mess, as engineering teams grow in size, it's necessary to standardize development and operations. One area of focus at Lob has to do with container orchestration and standardizing how we run services at Lob by migrating from Convox, Heroku, and on-off Infrastructure to Nomad. By prioritizing some technology over others we are able to improve the developer experience and avoid stretching ourselves—and those we support—too thin. Basically, Nomad will help us avoid reinventing the wheel with every new app at Lob.
But rethinking is hard. Our Platform team at Lob was challenged with constructive questions like, “Why do we need _one _container orchestrator? Why can’t I just figure out how to host my app myself?” and “Why Nomad, and not this other great technology?”
Since “because I said so'' works about as well on a group of developers as it does on a toddler (that is, not at all), we needed to provide a better answer. TL;DR: Nomad rocks; it's not only better than our current solution, but superior to other options.
Here’s how we justified the cost of migrating from the current stable workflows to the next-gen Nomad platform.
3 Pillars of Power
These are the three main draws to any container orchestrator, but Nomad makes these not just easy to express, but expressible with precision, which is important when managing services at scale.
| Deploy Containers | Scale Deployments | Rolling Releases |
| Nomad deploys your containers based on a Job Manifest (specification) | Based on load and/or metrics Nomad scales your application horizontally to handle changes in load. | Nomad handles rolling releases including health checks, blue/green deploys, and canaries. |
Nomad accomplishes the goal of deploying Dockerized applications, and it does so along with other features that make that a rich experience. In the simplest version of any container orchestrator, you give it an image and it runs that container for you. Unfortunately, that's really limiting, because if you just have one container, if it dies for some reason, then your app is down. A container orchestrator has to do more; it has to scale your containers out horizontally which is easier said than done; if we scale too aggressively we waste money on containers that go under-utilized, but if we under-scale we impact performance and our customers.
Nomad solves this “scaling” problem for us in a flexible yet powerful way. We provide Nomad with a minimum and maximum for the number of containers we want to run. Then we provide an Autoscaling Policy which includes a query, some external data source, and a strategy, what to do based on that data. Using this we can scale our service up and down based on simple metrics like CPU and Memory but we can also scale based on metrics like the messages in a Queue, the number of incoming requests, or the phase of the moon.
Another pillar we love is rolling releases. In our current tool, a release is going to steamroll; your app is going to deploy and there's not really a lot of nuance to how that change is rolled out. With Nomad, you're able to dictate how you want to roll your release out. You can say, "I want to auto-promote my release if it passes health checks,” or “I have some canaries that run, and based on how those canaries do, we will promote or roll back." With a manual promotion, you could indicate, "Deploy the canaries, but then let me click the button to complete the promotion." So much control!

Under the Hood
To fully appreciate Nomad it’s helpful to understand a few underlying key principles. There is much more but these are the ones we think you need to know about.
**Job Manifests **are plain-text files that describe how to deploy and manage a service including containers, network access, autoscaling, upgrade strategy, and sidecars! You can think of this like a specification for how to run your app. (Nomad’s version of all of the Kubernetes *.yaml manifest files)
Nomad Groups are collections of related containers that should be scheduled together (similar to a K8 Pod). Groups of containers are scaled up and down together on the same VMs. Example: Your main API container + monitoring sidecar + Startup Task.
Tasks are Docker Containers. Nomad Tasks can specify a Docker image, startup command, dynamic configuration files, and CPU + Memory allocation.
Services expose a Task to incoming network traffic. Services are registered in Consul and network traffic is routed via Traefik. Service can scale based on CPU + Memory utilization as well as any Datadog query.
Constraints (and Affinity) allow you to schedule apps on specific Compute Clients within a Nomad Cluster. Think: CPU Architecture, has GPU, AWS Region, Docker version, etc. This is a pretty powerful feature we are not yet using at Lob but when it comes time to squeeze the most out of our hardware, we will.
So why not something else?
Let’s address the elephant in the room: Kubernetes aka K8s. We won’t get into reasons why it may not be a fit for you (Matthias Endle made a great case here) but for us, Nomad is the better choice. This article from HashiCorp provides insight as to why but to sum up, we’ve placed a lobster icon (for Lob) on the graphic below.
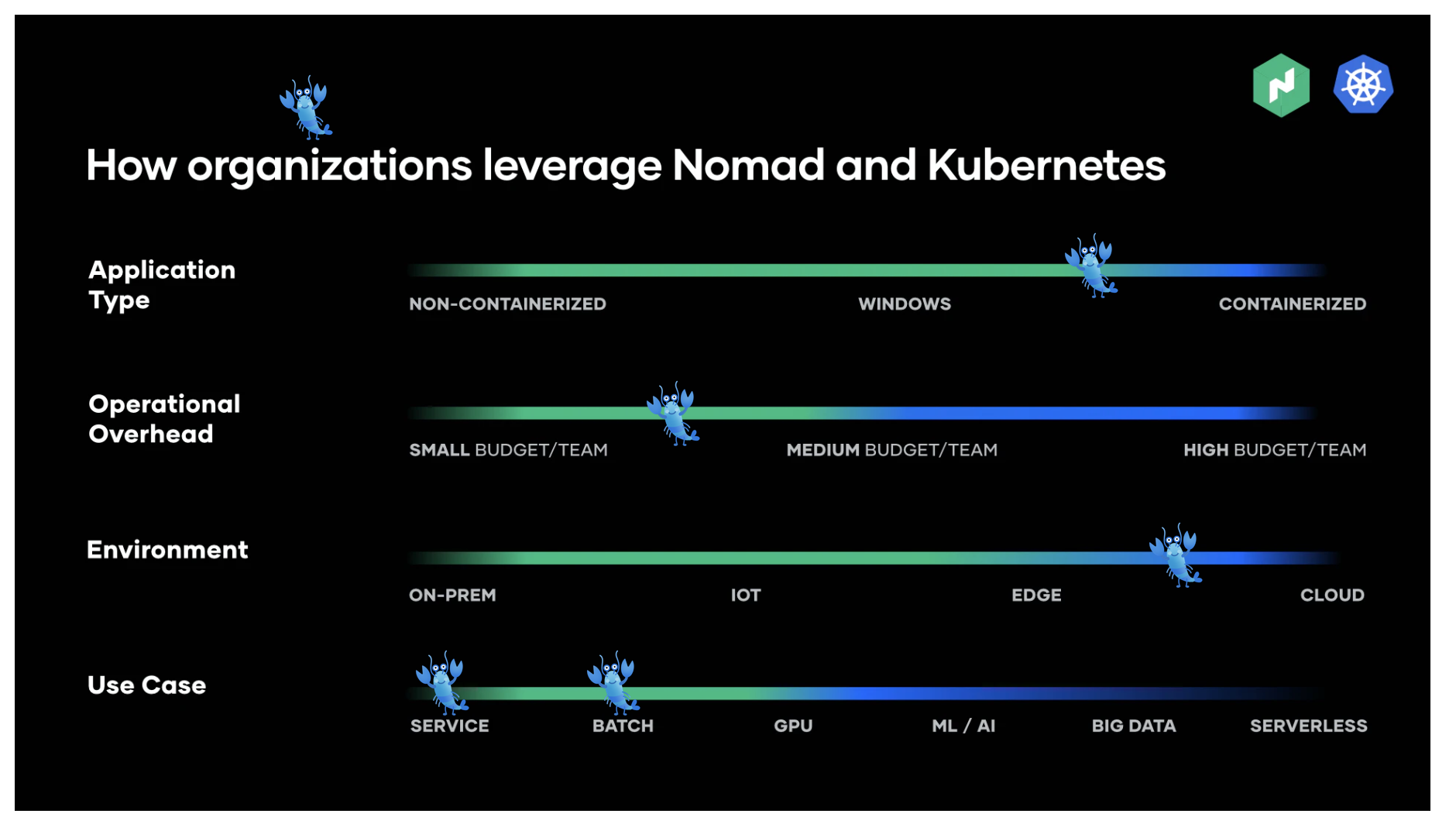
In short, Nomad offers a rich feature set that gives us all the benefits of K8s, both operationally and from a developer perspective, without the complexity.
Our current tool served us well for many years, but Lob’s engineering requirements out-grew its feature-set. For example, it only supports Level 7 Application Load Balancers, limiting our ability to handle lower-level networking ourselves. It also limits our ability to roll out updates including blue/green deploys, canary deploys, and auto-promoting based on complex service checks.
Lambdas are another option which offer really useful scaling features, but in most cases, a containerized service offers a better dollar-to-performance ratio. Many Lambda apps can be containerized, but not all containerized apps can be made into Lambdas, so we default to containerization.
Finally, it certainly didn’t hurt that we had engineers on staff experienced with Nomad which gave us a jump start.
For these reasons our team believes Nomad is capable of hosting 90% of workloads at Lob replacing all use of our existing orchestration tools, and replacing many uses of bare EC2 instances and Lambdas. Or in geek-speak, Nomad is powerful enough to be that one platform…to rule them all.

Friends of Nomad
Nomad doesn’t work alone; the following is our “Lob Stack” of applications that work together along with an indication of how. Note these are all open-source tools we are leveraging; we did not build them and that comes with choices that we made and quirks that make us different from other companies using Nomad.
| Nomad | Consul | Traefik | Github Actions |
| Container Orchestrator | Service Catalog, Key Value Config Storage | Container Load Balancing, [Auth] Middleware(s) | Builds Releases, Deploys Release Artifacts |
(Oh, and while we dig Traefik, I think we all can agree it’s an awful name. In case you, too, have to settle an internal debate, it’s pronounced “traffic.” )
Transitioning to Nomad
There were a few changes we had to make to transition to Nomad. Both are hosting services in AWS. This means permissions and backing-services work the same in both environments. Nomad runs Docker containers so the way an app is packaged and deployed is largely unchanged.
The build systems between the two platforms are very different. Our existing tool does a build plus a deploy to each “rack,” handling the entire release. Nomad doesn’t care about your code; it only accepts Docker images. Nomad only handles Deploy, so we build and then hand off a release artifact to Nomad to be deployed. Previously, our tool would rebuild your code every time you deployed it—to heck with that—now Lob builds once and deploys everywhere!
Another change is the syntax we use to express how to run our code. Our existing tool uses YAML like Docker Compose; this makes for simple config files, but it’s not as expressive as we would want (we can’t tell it to deploy canary for example). Nomad on the other hand uses HCL and passes config variables at deploy time.
Previously, our environment variables were stored in a database by our tool whereas Nomad doesn’t really have a db for that. Instead, we have variable files (JSON) that get passed to the Nomad config. Nomad can also leverage Consul to store dynamic configuration data, but Lob has not needed to use this integration.
The final difference worth mentioning is the hardware construct. Our existing tool has one rack per hardware option which creates undesirable isolation and the inevitable “Where’s Waldo?” of trying to seek and find where your app is running. Versus Nomad which can run a mix of compute nodes like different hardware, different operating systems, spot instances – all on one cluster with apps choosing where and how their app is run within that cluster! (Note: Nomad runs Docker on VMs, Our existing tool uses ECS.)
Conclusion
A single container orchestrator—and specifically the powerhouse Nomad—offers our team a standardized platform and process to stand up apps more quickly and easily. Nomad also offers us a flexible, robust feature set and unparalleled scalability in our applications and operations. By presenting details about the new solution and relating it specifically to our current state we were able to get buy-in from our engineering teams. We expect to have the majority of services (50+) migrated to Nomad by the end of Q2, and all apps done by Q3 (fingers crossed!).
Content adapted from a presentation by Senior Platform Engineer Elijah Voigt.
PS. For more on Nomad, check out Learn Nomad Orchestration: DevOps and Docker Live Show ## Bret Fisher interviews Erik Veld, Manager, Developer Advocacy at HashiCorp who shares how Nomad basics, demos, and what’s going on in the Nomad project.




